
Once the classifier has been trained, either with pre-trained excel or online, it is possible to apply the classifier on new texts/customer feedback.
As a rule of thumb, we say it requires about 300 cases per category to get a good accuracy (about 80%), But that depends on many factors. You will probably need more cases if the categorization is complex, there are many categories or if it is a difficult to separate the categories, i.e. you have similar feedback in two or more categories.
It is also in general more difficult to learn small categories, i.e. if you have a category of 1% of all trained verbatim and the other categories have 20-30%, the bigger ones easily overshadow the smallest.
With more cases for each category, we can fine tune the classifiers and obtain classifications that are more accurate. It is also recommended to keep the number of categories on the first level low (not more than 5-8 categories and use second levels if you want to deep dive into specific categories).
Accuracy and Recall
There are two important measures for assessing the quality of a classifier: Accuracy and Recall.
Accuracy is the % of correctly classified cases.
Accuracy can be measured either by category or totally for all the categories. Let us for example suppose that you use your Classifier to classify a validation set with 300 verbatim and further suppose that after doing the analysis we see that 100 cases are classified as Positive and 200 as Negative.
Of the 100 Predicted Positive 70 are correct and the rest, i.e. 30 are wrongly classified.
Of the 200 Predicted Negative 150 are correct.
Then we have:
- Number of verbatim is the validation set = 300
- Predicted Positive = 100
- Predicted Negative = 200
- Accuracy of category Positive: 70/100 = 70%
- Accuracy of category Negative: 150/200 = 75%
- Overall accuracy: (70 + 150) / 300 = 73.3%
Typically, to verify the accuracy we use a validation set of 200-300 cases and count the correct/wrong classifications.
Recall is the other important metric for classifier quality.
Recall is the % of cases "captured correctly" by the classifier.
Let us take the previous example and assume there are 120 Positive and 180 Negative verbatim in the validation set (i.e. not looking at what the classifier is categorizing, but what is really the case). Of the 120 Positive 80 are classified as positive by the classifier. Of the 180 Negative 160 are classified as negative. Then we have:
- Number of verbatim is the validation set = 300
- Number of Positive = 120
- Number of Negative = 180
- Recall of category Positive: 80/120 = 66.6%
- Recall of category Negative: 160/180 = 88.9%
- Overall Recall: (80 + 160) / 300 = 80%
Let’s now make a practical example in order to show how these measures can be used to improve classifications.
Improving classifications
We suggest having one validation set for checking the level of accuracy and recall and different test set for improving the quality of your training set. The categories used in our example are “PRICE” and “NO PRICE”.
You can find the example files, Price_train.xlsx and Price_test1.xlsx attached to this article and also by clicking the links within file names. The validation file to be classified is Price_validate.xlsx.
Once the training is done, let us calculate the level of accuracy or recall on the validation set that in this case has two categories "PRICE" and "NO PRICE" and fifty entries.
So, upload the validation set choosing as type "classification", click on "Submit" and go to "Export data" to download the result:
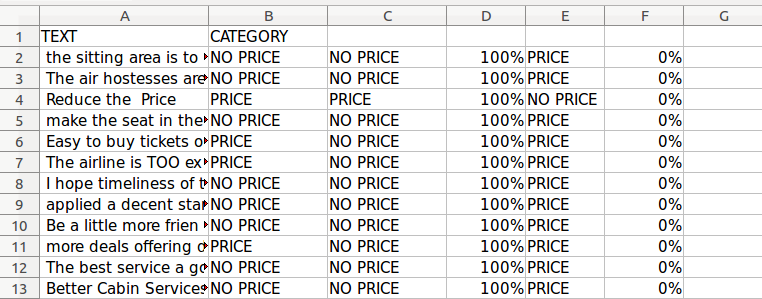
Now, let us calculate the level of accuracy and recall. To do this we compare the columns B (the correct category) and C (the category predicted by the classifier).
Calculating accuracy and recall is actually quite easy. In our example, we have 24 positive cases (PRICE) among 50 cases. You compare this with the classifier predictions, and when you get the actual results you sum up how many times you were right or wrong. There are four ways of being right or wrong:
- TN / True Negative: case was negative and predicted negative
- TP / True Positive: case was positive and predicted positive
- FN / False Negative: case was positive but predicted negative
- FP / False Positive: case was negative but predicted positive
Article contents are to be updated later.
Comments
0 comments
Article is closed for comments.