
In order to manage the process in a smooth way and avoid confusion, we strongly recommend using the following concepts:
- Training set: a file containing verbatim which was pre-classified. Can be used to train the classifier to recognize the right categories.
- Test set: a file that contains only verbatim and that is used to test the accuracy of the classifier. Afterwards, this set is manually checked, corrected, and can then used as a new training set.
- Validation set: a file used for accuracy benchmark. With both verbatim and categories.
- Source set: contains all the texts/feedback which needs to be classified.
- Results set: a file with verbatim and categories classified by VoC Classify.
Classifiers can be trained and tested either by using excel files where the right categories are already pre-defined (alternative A below) or by using training files where no categories are defined (alternative B).
The typical flows in VoC Classify for these scenarios are the following:
A. Training the categories using pre-categorized excel.
A simple way to train VoC Classify is to use pre-categorized excel files. In this way, the training file is prepared outside the tool in excel and is then uploaded to be processed. The steps of the flow are shown below.
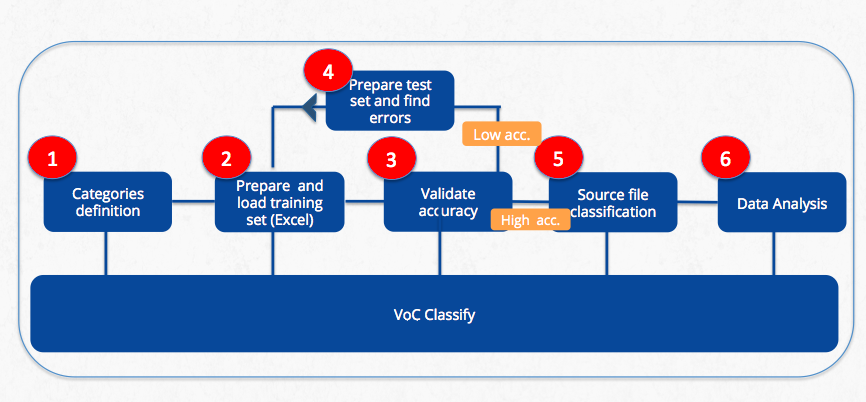
B. Training the categories directly in the tool
A second way to train categories can be done directly in the tool. In this case we just need an excel file that contains open feedback. The steps of the flow are shown below.
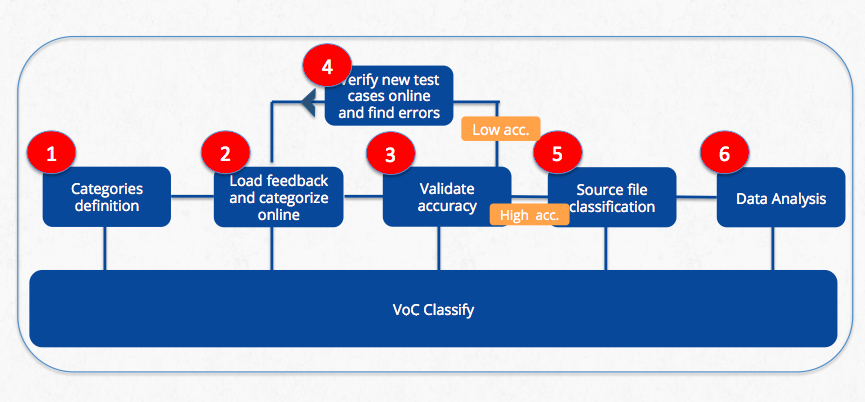
Validation is required to assess the accuracy of the training. Usually, an accuracy of 80% or above is considered good. To measure the accuracy we suggest to prepare a validation set with 200-300 verbatim and then count the number of correct and wrong categories. You can read more about this in the article "Methodology: How to improve VoC Classifiers".
Comments
0 comments
Article is closed for comments.