Validating your Classification Model
Etalon File
Once you have trained your Classification Model, you will also want to check how well it can perform on new data, ie you want to validate its performance.
This can be done with the use of a test file we refer to as an etalon file.
The etalon file, similarly to the training file, contains pre-labelled examples of verbatim for each category that can be used to test the quality of the classification model.
The accuracy calculation will check the label the verbatim should have (ACTUAL) vs what the model has PREDICTED and give a score of how well it can predict new data.
The Etalon must contain data that the model has not seen before, ie data that was not used in the training file.
We usually recommend that the etalon file should have about 20% of the training examples of each category. For example, if your training file has 1000 examples for the Negative category, then the Etalon should have 200 examples for the Negative category.
Sometimes it’s easier to take your full labeled dataset and split it into 80%-20%, where the 80% part will be used for training and the 20% will become the etalon file.
To add the Etalon file to a particular Classifier Model, go to Classify -> Upload -> Upload New File and choose “etalon classification” as the type. The format of the file should be identical to the training file containing CATEGORY, TEXT columns.
Although the Title for the etalon file is optional, we strongly recommend to enter a meaningful title as it will make the next steps in Accuracy Validation process more transparent.
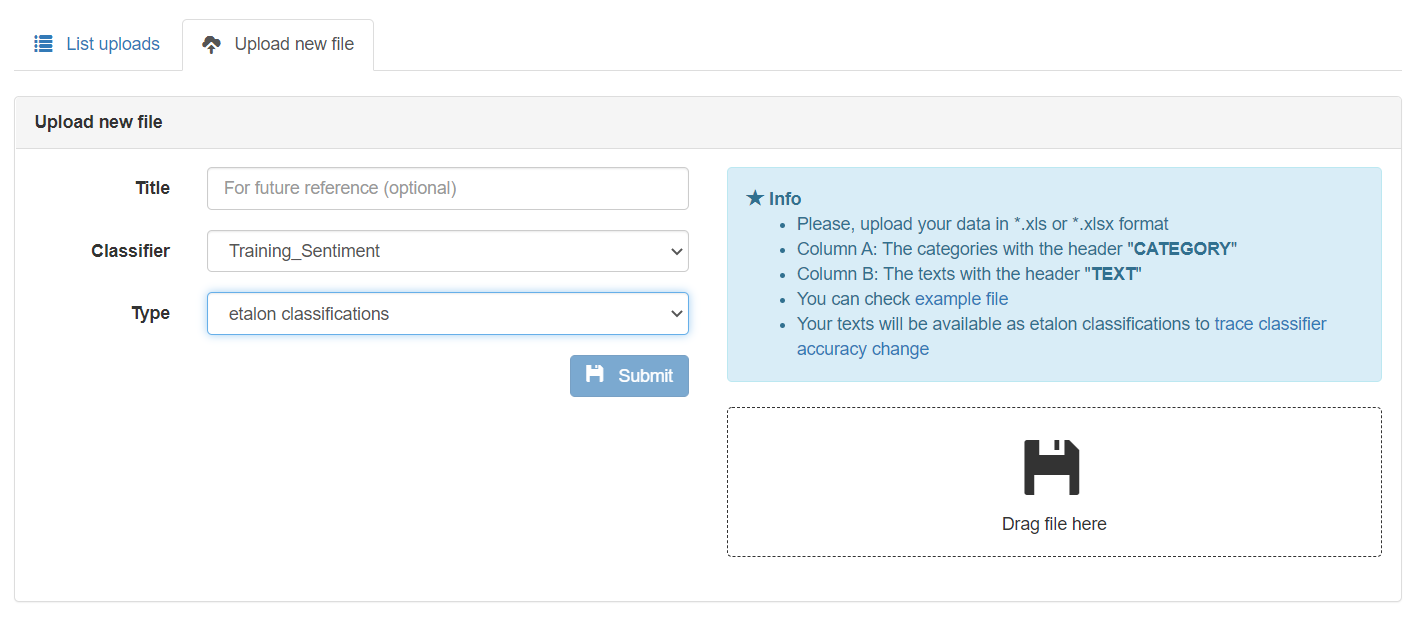
When an etalon file has been uploaded to a particular Classification Model, an additional button will become available in the Model view. This button allows the user to run the Accuracy Validation calculation against the uploaded Etalon file.
Structure of the Etalon file for Multitopic classification
The general required format for the Etalon file is two columns - CATEGORY and TEXT, where CATEGORY represents the actual category label of the Verbatim (TEXT).
This structure works for both single and multi-topic classification Etalon files, where for multitopic classification you will see the same Verbatim several times (duplicated) with a different category. This tells the model that the specific Verbatim belongs to these multiple categories.
For example, your Etalon (and training file) could look like this:
|
CATEGORY |
TEXT |
|
Price_Product |
The staff in the shop were rude but your prices are fair |
|
Staff |
The staff in the shop were rude but your prices are fair |
|
Shop |
The staff in the shop were rude but your prices are fair |
You can also use the format below for structuring your Labelled files. In this case each Verbatim is on a single line but the Categories are listed with a | (pipe) delimiter.
|
CATEGORY |
TEXT |
|
Price_ Product | Staff | Shop |
The staff in the shop were rude but your prices are fair |
Both formats are valid and you can choose which to use depending on the format of your original data.
Accuracy Validation
After you click the “Verify Accuracy” button you will be taken to the Accuracy Measurement page.
Here you can first select the Classifier Model you want to evaluate and then the relevant Etalon file.
If you have not specified a Name for the Etalon upload, you will see “not specified” as below, otherwise you will see the given Etalon upload title. If you have more than one Etalon uploaded for a Classification Model, you will see them all listed in the box
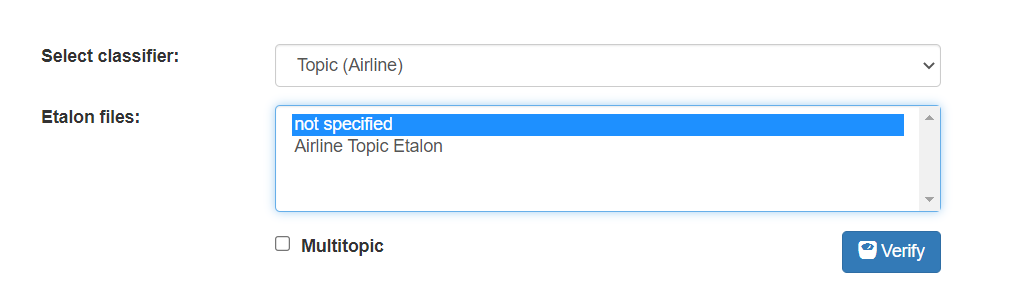
Single-Topic Validation
If your Classification Model is a single topic model, e.g. Sentiment, you can simply run the accuracy calculation with the Verify button.
What you will see is a summary of the standard Machine Learning metrics for your selected model.
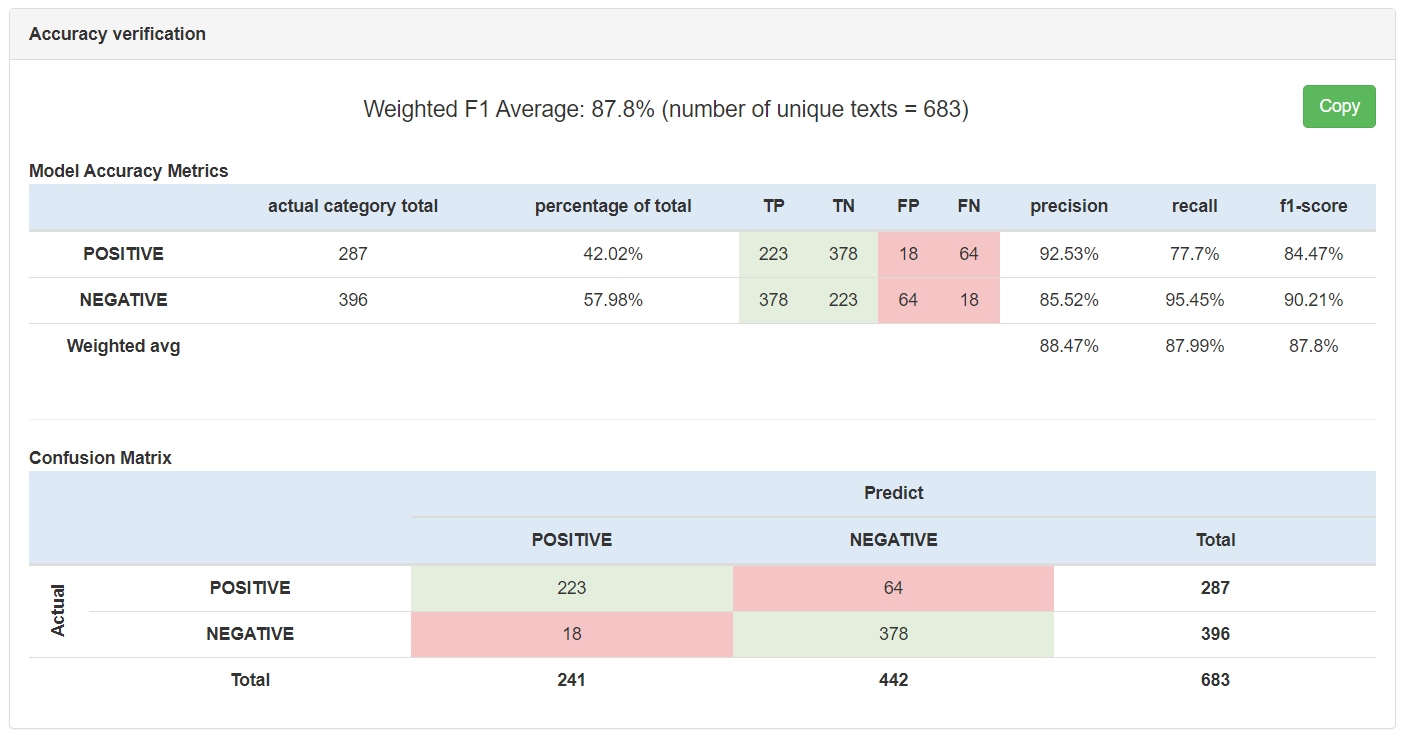
The Weighted F1 Average represents the f1-score of the model and is weighted based on the number of category examples in the Etalon file so that the f1 Score isn’t skewed by less represented Categories.
n=683 represents the number of unique verbatim examples in the Etalon file. This can be lower than the total number of records in the Etalon file as it is possible to have duplicate verbatim examples. The accuracy calculation only takes the unique examples into account.
The first table gives you the Model Accuracy Metrics summary per category:
- Total: number of unique ACTUAL verbatim examples per category in the etalon file
- Percent: the percentage of the category examples of the Total (n) to understand the distribution of each Category examples
- TP: The number of True Positive examples the model predicted
- TN: The number of True Negative examples the model predicted
- FP: The number of False Positive examples the model predicted
- FN: The number of False Negative examples the model predicted
- Precision: Precision is a measure that tells us what proportion of verbatim that were classified as Positive were indeed Positive. This is calculated as TP/(TP+FP)
- Recall: Recall is a measure that tells us what proportion of verbatim that were actually Positive were predicted by the algorithm as Positive. This is calculated as TP/(TP+FN)
- f1-Score: this is known as the harmonic-mean between Precision and Recall to give a Machine Learning algorithm a single performance metric. This is calculated as

Example. We have a binary classification model for Spam (spam / not spam). In etalon of 100 verbatim 5 are ACTUALLY spam. Let’s say our model is very bad and predicts every case as Spam.
Precision. Since we are predicting every verbatim as spam, our denominator(True positives and False Positives) is 100 and the numerator, verbatim being spam and the model predicting his case as spam is 5. So in this example, we can say that Precision of such a model is 5%.
Recall. Our denominator(True positives and False Negatives) is 5 and the numerator, verbatim being spam and the model predicting his case as spam is also 5 (since we predicted 5 spam cases correctly). So in this example, we can say that the Recall of such a model is 100%.
f1-Score. Based on values of Precision and Recall, we can calculate an overall f1-Score. It’ll be equal to 9.5%. SInce f1-Score is a harmonic-mean, it won’t show good results if one of the metrics are too small. Thus, it’s a proper metric to evaluate Precision and Recall in a consolidated way
For a given class, the different combinations of recall and precision have the following meanings:
high recall + high precision : the class is perfectly handled by the model
low recall + high precision : the model can’t detect the class well but is highly trustable when it does
high recall + low precision : the class is well detected but the model also include points of other classes in it
low recall + low precision : the class is poorly handled by the model. To improve the model accuracy it is recommended to review the training file for incorrect labels and to provide more relevant data for the low performing categories so the model can learn better.
The second table gives you the Confusion Matrix showing the intersection of ACTUAL and PREDICTED values per category. Note that these are the same as the TP and FN values in the first table, just represented differently.
Multi-Topic Validation
If your Classification Model is multitopic (ie a verbatim can have more than one matching categories), you need to run the Accuracy Validation with some additional parameters.
First check the Multitopic box and you can then select the required Threshold and Categories Count parameters. Please refer to Multitopic Classification article for additional information.
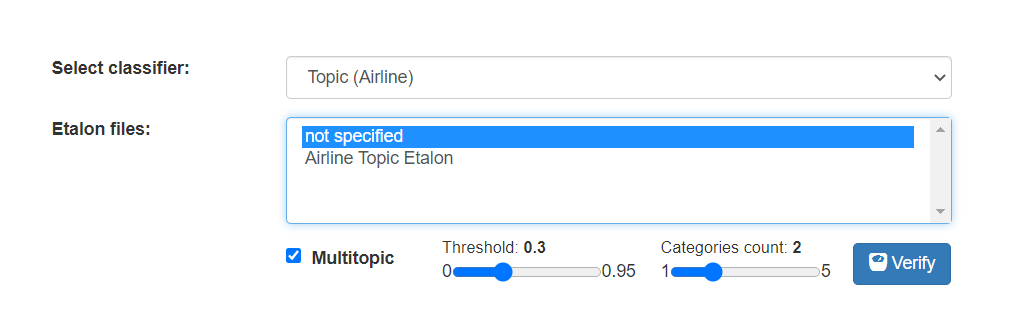
When you click Verify you will see a very similar output to the Single-topic Accuracy Interface.
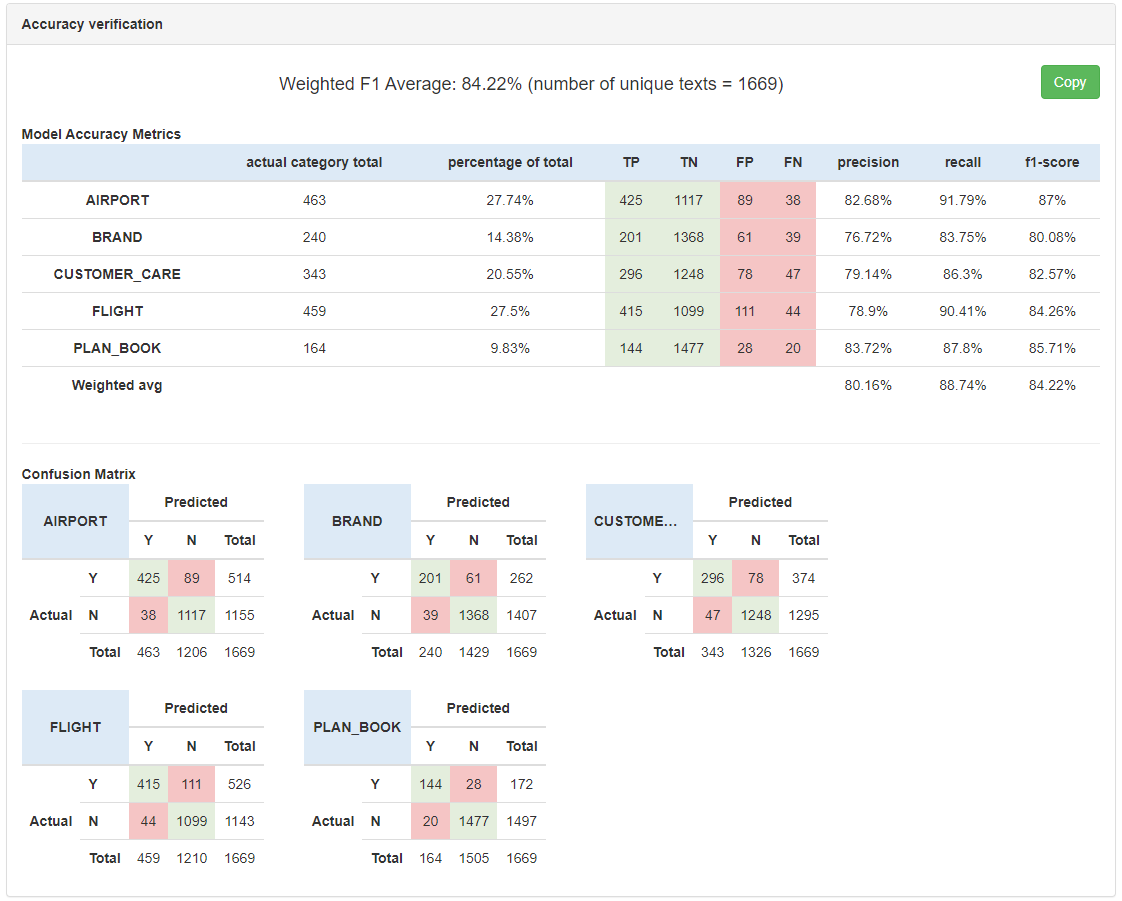
The main difference here is that instead of seeing a single Confusion Matrix table you are now presented with individual Confusion Matrices for each category, showing the TP, TN, FP and FN values.
Further Reading on Machine Learning Metrics:
Comments
0 comments
Article is closed for comments.